

Introduction
Materials and Methods
토양 채취 및 특성분석
토양 색상 변수 추출
토양 OM 예측모델 개발 및 검증
Results and Discussion
Pearson 상관관계 분석
토양 OM 예측을 위한 알고리즘의 성능 비교
토양 OM 예측 모델 검증
Conclusion
Introduction
토양의 다양한 이화학적 특성 중 유기물(organic matter, OM) 함량은 작물 생산량과 토양 질을 결정하는 중요한 요인이며, 지속가능한 토양 관리를 위한 필수 지표 중 하나이다(Kang et al., 2024). 국내 농촌진흥청(Rural Development Administration, RDA)에서는 토양의 생산성 확보를 위해 토지이용 유형별 최적 OM 범위를 2.0 - 3.0%로 제시하였으며, 매년 토양 조사를 통해 주기적으로 OM 변화를 모니터링하고 있다(Hyun et al., 2022; Shin et al., 2024; 2025). 하지만, 기존의 토양 OM 함량 분석(예, Tyurin 법, Walkley-Black 법 등)은 장시간의 분석 시간과 노동집약적인 과정을 요구하며(Kim et al., 2025), 이는 지속적인 토양 OM 모니터링을 위한 시간적 및 비용적 부담을 증가시키는 한계로 작용한다(Baumann et al., 2016; Kang et al., 2022). 또한, 최근 환경 분야에서 이슈가 되고 있는 미세플라스틱(microplastic, MP) 분석 중 토양 OM의 교란으로 인해 분석의 정확성이 감소할 수 있다고 보고된 바 있다(Kang et al., 2025a). 이러한 배경에서, 최근에는 토양 내 OM 함량을 직접 측정하는 것이 아닌, 머신러닝(machine learning, ML) 알고리즘 등 AI 기술을 활용하여 토양 OM 함량을 추정하는 기술에 대한 연구가 각광받고 있다.
토양 색은 OM 함량을 포함한 다양한 토양 물리화학적 특성(예, 수분함량, 온도, 미생물 군집 등)을 간접적으로 반영하는 지표로 활용되며(Swetha et al., 2022; Dai et al., 2024), 이는 주로 빨강(red, R), 초록(green, G), 그리고 파랑(blue, B)으로 구성된 RGB 값 형태로 표현된다. 하지만, 이러한 RGB 값은 외부 환경조건(예, 빛, 구름 등)에 의한 변동성이 크며, 토양 색상 차이를 직관적으로 해석하는 데에 한계가 존재하여 명도, 색상, 그리고 채도와 같은 변수를 기반으로 다양한 색 변수 조합으로 변환되어 활용된다(Sonn et al., 2022; Kang et al., 2024). 또한, 토양 색상은 추출 장비에 따라서도 다르게 표현될 수 있다. 그중, 스마트폰은 고가의 분광기나 전용 색도계와 달리 접근성 및 활용성이 매우 뛰어나며, 별도의 전문 지식이 없어도 현장에서 즉각적으로 토양 색상 정보를 얻을 수 있다는 장점이 있다. 하지만, 스마트폰은 모델 혹은 제조사에 따라 카메라 기능의 성능 차이가 존재하며, 이는 동일한 토지이용 유형에 적용하더라도 수집된 토양 색상 정보가 상이하게 나타날 수 있음을 시사한다.
따라서, 본 연구에서는 다양한 스마트폰을 기반으로 구축한 토양 색상 데이터베이스를 활용하여 국내 농경지 토양의 토지이용 유형별 OM 예측 모델을 개발하고자 하였으며, 이를 통해 기존 토양 OM 분석의 한계점을 보완하고 현장 적용이 가능한 새로운 OM 함량 분석 패러다임을 제시하고자 하였다.
Materials and Methods
토양 채취 및 특성분석
농경지 토양 시료는 대전광역시와 세종특별자치시를 포함한 충청지역 내 142개 농경지에서 3반복 채취하였으며(Fig. 1), 작물 별 재배 일정을 고려하여 2021년 6월부터 2022년 5월간 실시하였다. 시료 채취는 Eijkelkamp (The Netherlands)사의 single gouge auger를 이용하였으며, 채취한 토양 시료는 층위(0 - 70 cm)에 따라 총 1,459개로 구분하였다: 0 - 10 cm (n = 210), 10 - 20 cm (n = 210), 20 - 30 cm (n = 210), 30 - 40 cm (n = 210), 40 - 50 cm (n = 210), 50 - 60 cm (n = 210), 그리고 60 - 70 cm (n = 199). 이후, 전체 토양 시료는 토지이용 유형에 따라 다음과 같이 구분되었다: 밭 토양(n = 831), 논 토양(n = 499), 그리고 과수원 토양(n = 129). 채취한 토양 시료는 OM 함량 분석을 위해 105℃로 설정한 건조 오븐에서 48시간 동안 수분을 제거하였으며, 2 mm 체에 걸러 시료를 준비하였다. 준비된 시료는 원소분석기(CHN828, Leco Corp., USA)를 이용하여 TC-IC 법을 이용하여 유기탄소 함량을 분석하였으며, 분석한 결과에 환산계수(1.724)를 대입하여 토양 OM 함량을 계산하였다(Van Bemmelen, 1897; Table 1). 토양 OM 분석한 결과는 Leco사의 교정용 EDTA 시료를 3반복 분석한 평균 값을 이용하여 3회 반복 검증하였으며, 회귀식의 결정계수(coefficient of determination, R2)는 0.995 이상이었다.
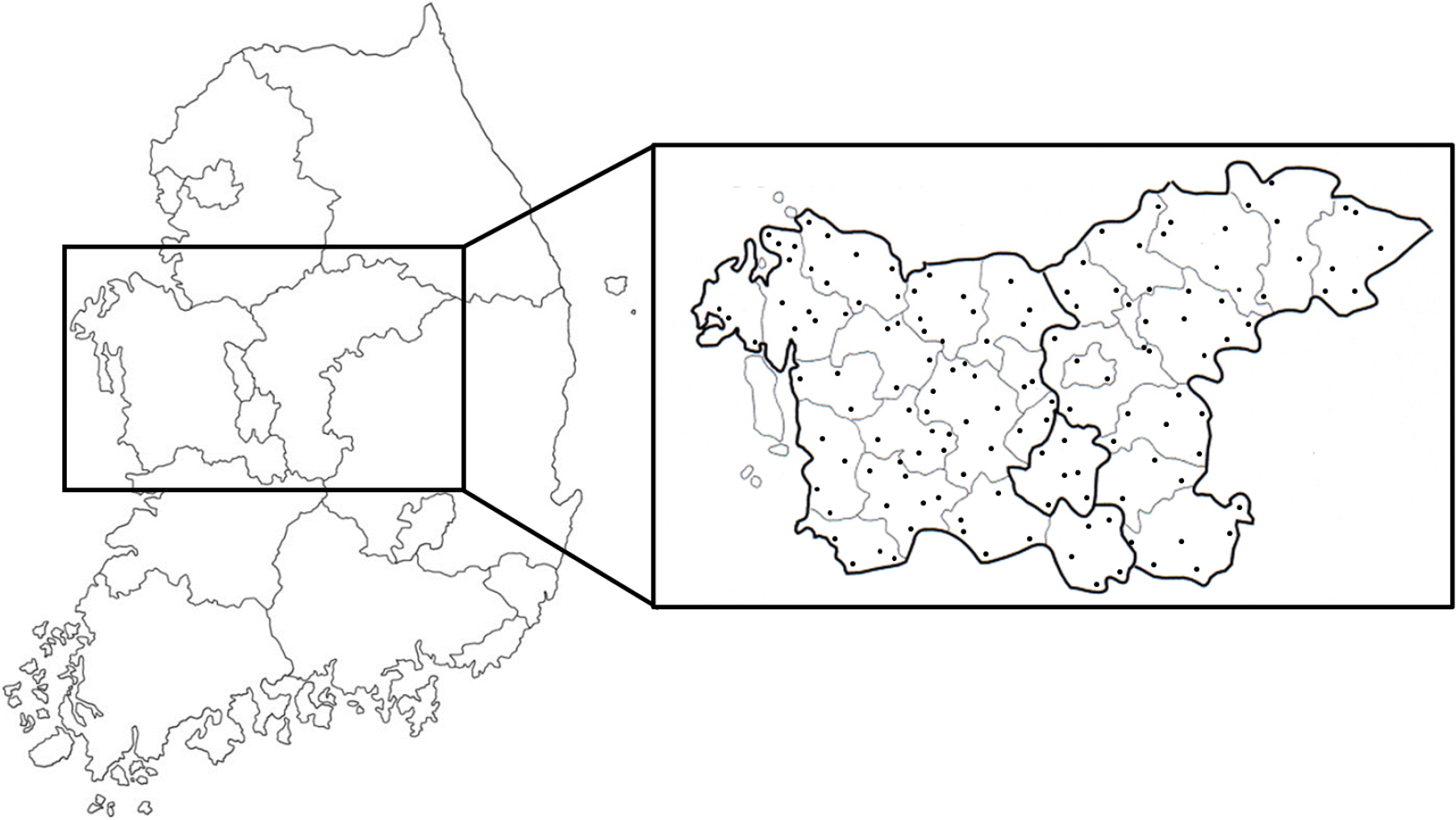
Table 1.
Brief summary of soil organic matter content used in this experiment (n = 1,459).
토양 색상 변수 추출
토양 색상은 암실 환경에서 1,200만 화소를 가진 4종(Samsung, LG, Apple, 그리고 Xiaomi)의 스마트폰 카메라로 촬영한 토양 단면 사진에서 추출하였으며, 토양 색상의 표준화를 위해 스마트폰은 촬영하기 전에 모든 보정 기능을 해제한 기본 모드로 설정하였다. 또한, 스마트폰을 이용한 토양 단면 사진은 자연광과 유사한 6,500 K 색온도 형광등 조명 아래 30 cm 높이에서 촬영되었으며, 토양 색상 값은 각 사진 내 토양 표면의 서로 다른 10지점에서 Color Cop software (Prall, 2007)로 RGB값을 추출하였다. 이러한 스마트폰의 종류와 모드 설정은 각 스마트폰에서 발생할 수 있는 색상 값의 고유한 차이를 보정하기 위해 실시하였다(Fig. 2).

Fig. 2.
Image showing the soil samples taken with four different smartphones. A, Samsung Galaxy S10; B, LG V50 ThinQ; C, Apple iPhone 6S; and D, Xiaomi MI MAX 2. R, G, and B were indicated the red, green, and blue color combined of various color components (i.e., lightness, hue, and chroma), respectively.
이후, 얻어진 토양 RGB 값은 국제조명위원회(Commission Internationale de I’Elcairage, CIE)에서 제시한 색상 매개변수(예, CIE-XYZ, CIE-L*a*b*, 그리고 CIE-L*c*h*)로 변환되었다. 토양 색상을 나타내는 CIE 방식 중 토양 색상의 밝기를 나타내는 L*은 검정색(0)에서 흰색(100)까지의 범위를 가지며, a*과 b*은 각각 녹색에서 빨간색과 파란색에서 노란색의 색 영역을 나타낸다. 또한, c*와 h*도 각각 a*과 b*와 유사한 색 영역을 가지나, 변수간 차이는 색상을 표현하는 방식에 기인한다. 이러한 색상 값의 매개변수화는 토양 RGB 값을 인간의 시각 스펙트럼에 맞게 조정하여 기존보다 정밀하게 토양 색상을 나타내며(Kang et al., 2024), 스마트폰 기종에 따라 색상 값이 달라지는 실험적 오차를 줄일 수 있어 예측 모델의 성능을 향상시킬 수 있다(Robertson, 1977; Kang et al., 2024). 다음 식(1)부터 (3)까지는 토양 색상을 RGB 방식에서 CIE-L*a*b*와 CIE-L*c*h*로 변환하는 과정을 나타내었다.
식(1)은 RGB 값을 CIE-XYZ로 변환하며, 이는 식(2)에서 CIE-L*a*b*를 구하기 위한 CIE-XYZ를 계산하는 과정이다. 제시된 방정식에서 매개변수 Xn, Yn, 그리고 Zn은 기준 백색점의 값을 나타내며, 상수인 C1, C2, C3, 그리고 C4는 각각 116.0, 903.3, 500.0, 그리고 200.0의 특정 값을 나타낸다. 식(3)은 CIE-L*a*b*를 구하기 위한 CIE-L*c*h*로 변환하는 과정을 나타내며, 이 과정 중 h* 값에 따라 보정계수를 다르게 적용한다. 예를 들어, h* 값이 0° 미만이면 360°를 더하여 계산하고, 360° 이상인 경우에는 360°를 빼고 계산한다.
토양 OM 예측모델 개발 및 검증
토양 OM 예측모델 개발을 위한 통계 분석은 Python software (Python, 2022)를 이용하여 수행되었으며, 색상 매개변수와 토양 OM 간의 통계적 상관관계는 Python software 내 Pearson 법을 기반으로 평가하였다. 예측 모델은 전체 데이터 중 80% (n = 1,167)를 이용하여 구축하였으며, 나머지 20% (n = 292)의 데이터는 모델 검증에 이용되었다. 토양 OM 예측 모델에 사용된 ML 알고리즘은 다중선형회귀(multiple linear regression, MLR), 서포트 벡터 머신(support vector machine, SVM), 그리고 랜덤 포레스트(random forest, RF)로 총 3종이었다. 본 연구에서는 색상 변수와 토양 OM 함량 간의 선형 관계 규명을 위하 MLR 알고리즘에서는 일반 최소 자승법(ordinary least squares, OLS) 기법을 적용하였고, SVM과 RF 알고리즘에서는 회귀 모듈을 활용하여 토양 OM 함량을 예측하였다. 이때, 모델의 재현성 확보를 위한 RF 모델의 hyperparameter 중 n_estimators, max_depth, 그리고 random_seed는 각각 200, 10, 그리고 42로 설정하였으며, SVM 모델은 데이터 적용 전 standard scaler를 통해 표준화하였다.
개발된 예측 모델의 성능은 R2을 이용하여 평가하였으며, 예측 모델의 오류 지표는 평균 제곱 오차(mean squared error, MSE), 제곱근 평균 오차(root mean squared error, RMSE), 그리고 평균 절대 오차(mean absolute error, MAE)를 분석하였다(Kang et al., 2022; Lee et al., 2024). 또한, 예측 모델에 사용된 변수 간의 높은 상관관계로 인해 발생하는 다중 공선성을 피하기 위해 변동 팽창 지수(variation inflation factor, VIF)를 분석하였으며, VIF 임계 값은 Kang 등(2022)에서 제시한 방법론에 따라 5.0 미만으로 설정하였다.
위 식에서, yi는 전체 토양 시료에 대한 실제 값을 나타내며, y’i와 y’’i는 각각 i번째 토양 시료의 예측 값과 평균 값을 나타낸다. 또한, n은 토지이용 유형 별 전체 시료 수를 의미하며, ri는 i번째 매개변수를 제외한 예측 모델의 R2 값을 나타낸다.
또한, 모델 성능이 특정 지역 혹은 토지이용 유형에 의해 과대평가되는 것을 확인하기 위해 지역을 구분한 leave-one-site-out (LOSO) 분석과 k-fold cross-validation (k=10)을 수행하였다. 특히, LOSO 분석을 위해 토양 시료는 채취 지역에 따라 충청남도(n = 689), 충청북도(n = 451), 세종특별자치시(n = 190), 그리고 대전광역시(n = 129)로 구분하였다. 최종 도출한 토양 OM 예측 모델은 Omnibus와 Jarque-Bera 검정을 이용하여 모델의 정규성을 확인하였으며, 모델의 자기상관성은 Durbin-Watson 검정을 이용하여 평가하였다.
Results and Discussion
Pearson 상관관계 분석
토양 색상 변수와 OM 함량 간의 통계적 상관관계를 분석한 결과는 Fig. 3에 나타내었다. 총 8종의 토양 색상 변수 중 h* 변수(Pearson’s r = +0.611)는 토양 OM 함량과 양의 상관관계를 보였으나, 다른 7종의 토양 색상 변수는 모두 음의 상관관계를 나타내었다. 특히, 빨간색을 의미하는 R 변수는 OM 함량과 가장 강한 음의 상관관계(p < 0.01)를 나타내었으며, Pearson 상관관계 계수는 -0.468이었다. 색상 변수 간의 상관관계 분석 시, 일부 변수 조합에서 높은 상관관계(예, G - L*, b* - c*, R - G 등)를 나타내었으며, 이는 예측 모델의 다중 공선성이 발생할 우려가 존재하여 모델 구축 시에 제외되어야 한다(Sonn et al., 2022; Kang et al., 2024). 따라서, 본 연구에서는 높은 상관관계를 보이는 변수를 제거하여 최종 색상 변수 조합을 선정하였으며, 최종 선정한 3종의 색상 변수는 다음과 같다: L* (토양 색상의 밝기 정도), b* (토양 색상의 파랑-노랑 정도), 그리고 h* (토양 색상의 색조). 토양 색상 변수 중 L*과 h* 변수는 토지이용 유형 차이에 따른 유의한 변화를 나타내지 않는 반면, b* 변수는 토지이용 유형에 따라 토양 OM 함량과 다른 경향을 나타내었다. 특히, 밭 토양의 b* 변수는 +0.001로 약한 양의 상관관계(p > 0.05)를 갖는 반면, 논 토양, 과수원 토양, 그리고 전체 토양 시료에서는 각각 -0.290, -0.360, 그리고 -0.240로 음의 상관관계(p < 0.05, 0.01, and 0.05)를 나타내었다.
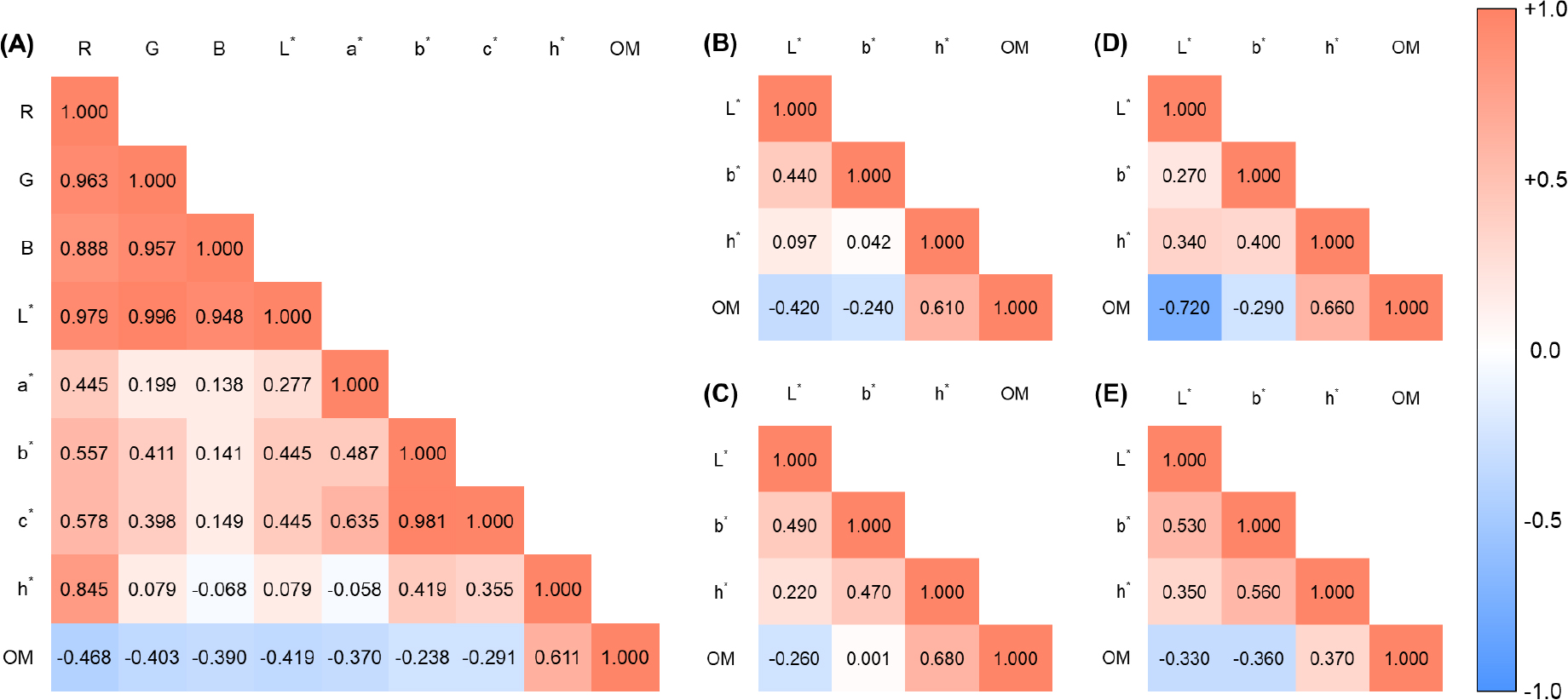
Fig. 3.
Heatmap representing the correlation between soil color parameters and organic matter (OM) content. (A) statistical relationship of entire soil color indices with soil OM content, while heatmap between selected features and soil OM content classified as entire sample (B), upland soil (C), paddy soil (D), and orchard soil (E), respectively, depending on the land-use types.
이러한 결과는 토양 색상이 어두워질수록 토양 내 OM 함량은 증가하는 선행연구의 보고와 일치하는 경향이었다(Baumann et al., 2016; Heil et al., 2022; Hyun et al., 2022; Sonn et al., 2022; Kang et al., 2024). 토양 색상은 다양한 유기물원의 투입에 따라 부식질이 축적되면서 색이 어두워진다고 알려져 있으며, 이 외에도 높은 수분함량, 바이오차 투입, 그리고 망간 및 철 산화물의 집적에 의해 토양 색이 달라질 수 있다(Swetha et al., 2022; Kim et al., 2024; 2025; Kang et al., 2025b). 이러한 다양한 요인에 의해 토양 색상이 달라질 수 있음에도 불구하고, 토양 색상에 따른 OM 함량이 일관된 방향성을 나타내었으며, 이는 본 연구에서 사용한 색상 방식(예, CIE-L*a*b*)이 토양 OM 축적을 잘 반영하는 지표로 작용하였음을 시사한다. 다만, Sonn 등(2022)과 Kang 등(2022)의 보고와 유사하게 본 연구에서도 일부 색상 변수 간의 높은 상관관계가 나타났으며, 다중 공선성 발생에 따른 모델 오류를 해결하기 위해 일부 변수를 제외하는 과정이 필요하였다.
토양 OM 예측을 위한 알고리즘의 성능 비교
토양 색상 지표를 기반으로 토양 OM 함량 예측을 위해 MLR, SVM, 그리고 RF 알고리즘을 적용하여 개발한 모델의 성능은 Fig. 4에 나타내었다. 전체 토양 시료에 대한 3개 알고리즘의 training R2 값은 0.728 (MLR), 0.732 (SVM), 그리고 0.741 (RF)로 유사한 반면, 예측 모델에 테스트 데이터를 적용한 R2는 알고리즘에 따라 다른 경향을 나타내었다. 특히, MLR 및 SVM 알고리즘은 테스트 데이터를 적용함에 따라 모델 성능이 각각 6%와 7% 감소하였으며, 이는 모델 성능이 특정 훈련 데이터에 과적합되었을 가능성을 의미한다. RF 알고리즘은 다수의 의사결정 트리를 앙상블 기법을 통해 구성함에 따라 데이터 유형에 따른 유의한 차이를 나타내지 않았다. 이러한 결과는 예측 모델을 토지이용 유형별로 구분하였을 때에도 유사한 경향이었으며, RF 알고리즘은 MLR과 SVM 알고리즘보다 안정적인 토양 OM 예측 능력을 나타내었다. 토지이용 유형에 따른 R2 값 비교 시, 논 토양 OM 예측 모델은 밭 토양과 과수원 토양보다 우수한 모델 성능을 나타내었으며, RF 알고리즘을 적용한 모델에서 0.759로 가장 높은 R2 값을 나타내었다. 모델의 오류지표는 R2와 상반된 경향을 나타내어 R2 값이 높은 RF 알고리즘 기반 모델은 MLR 및 SVM 모델보다 낮은 오류지표를 나타내었다(Table 2). 오류 지표를 토지이용 유형에 따라 분류하였을 때에도 알고리즘에 따른 차이와 유사하였으며, 논 토양, 전체 토양 시료, 과수원 토양, 그리고 밭 토양 순으로 낮은 오류 지표를 나타내었다.
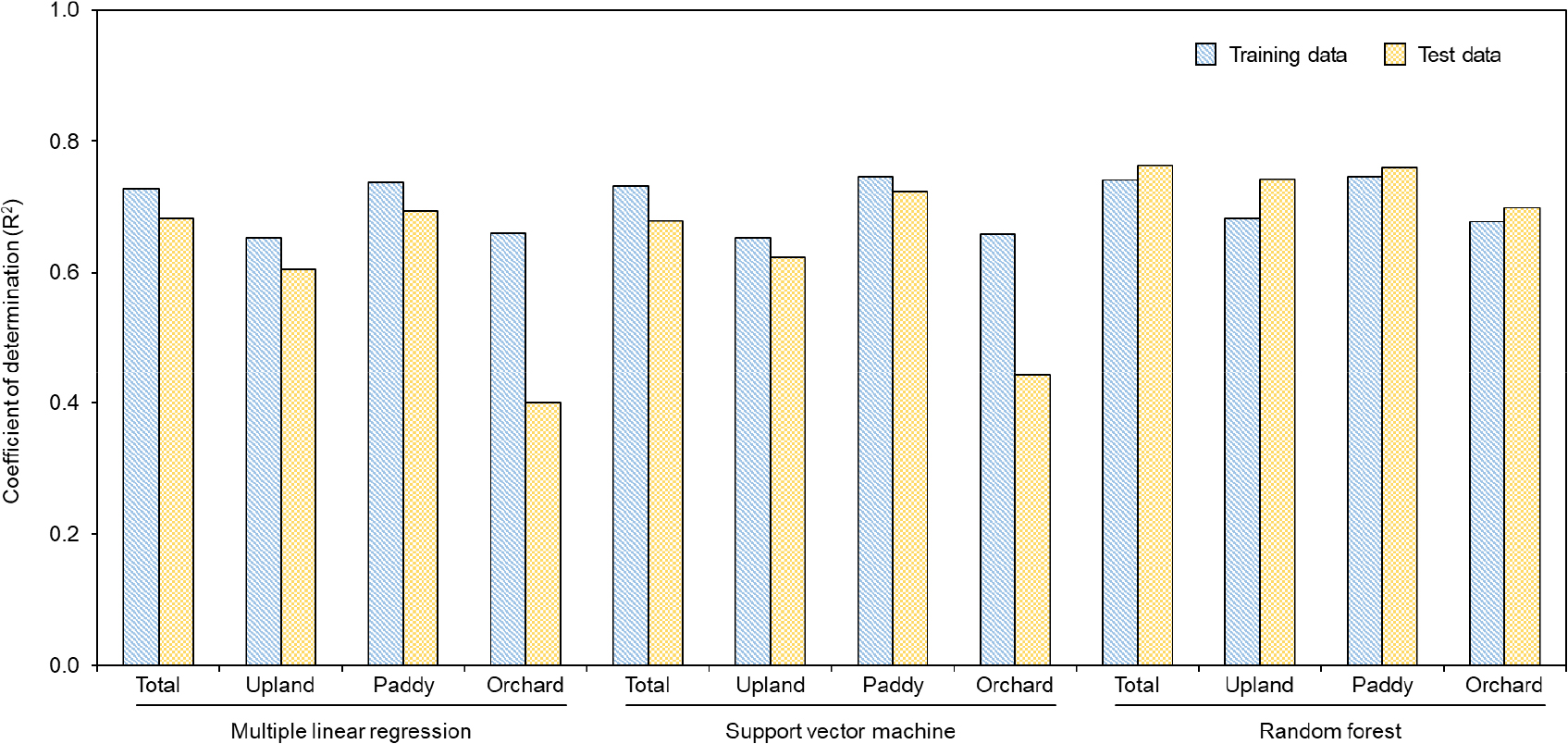
Table 2.
Residual analysis of the soil color-based regression machine learning (ML) models using three algorithms and four error metrics.
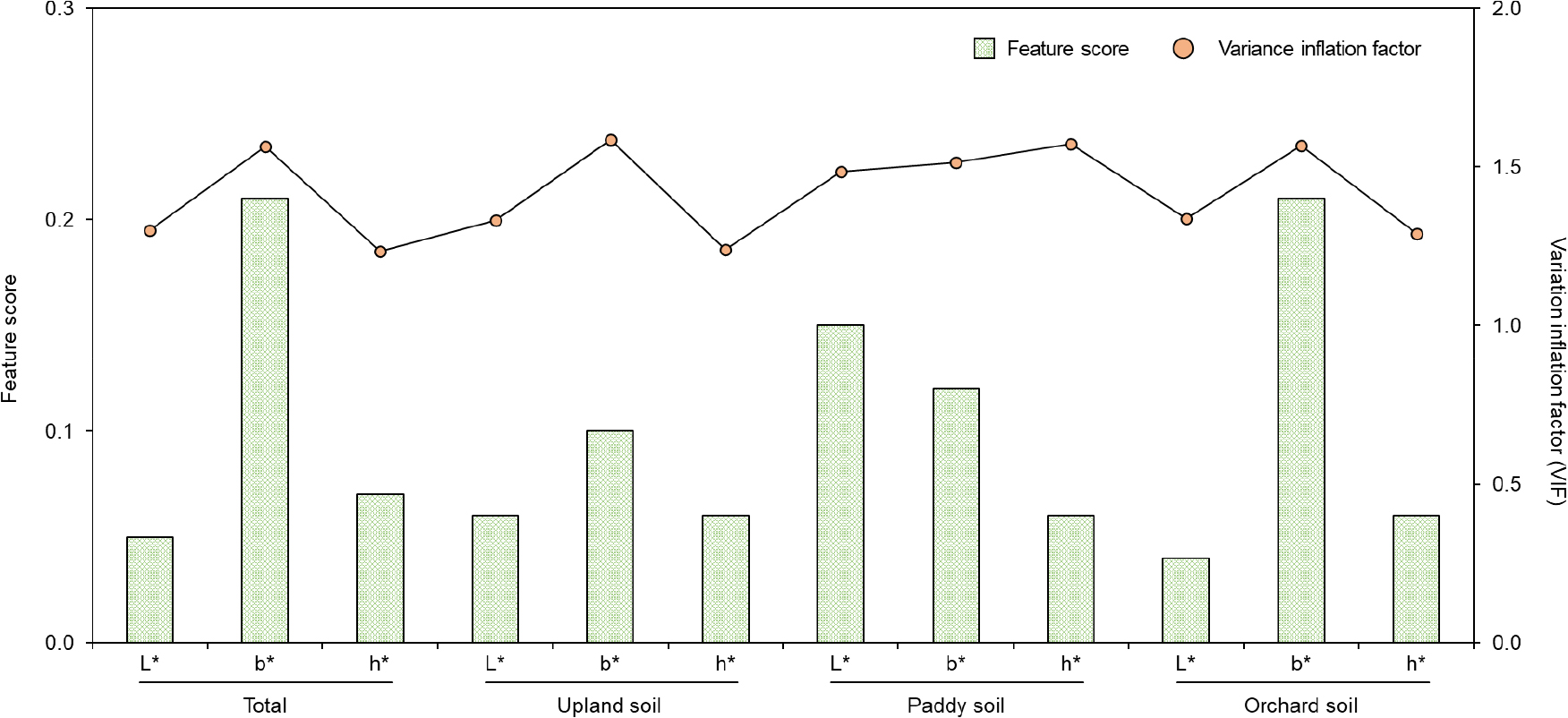
토양 내 OM 예측에 사용된 변수의 상대적 영향력과 VIF 값을 분석한 결과는 Fig. 5에 나타낸 바와 같다. 예측 모델에 사용된 3종의 색상 변수 중 b* 변수는 전체 토양 시료, 밭 토양, 그리고 과수원 토양에서 각각 0.21, 0.10, 그리고 0.21로 가장 강한 영향력을 나타내었으나, 논 토양에서는 L* 변수(0.15)에서 가장 높았다. 각 변수의 VIF 값은 1.233 - 1.585의 범위를 나타내었으며, 모두 임계 값 미만으로 조사되었다.
본 연구에서 도출한 RF 알고리즘으로 훈련된 모델은 테스트 데이터를 적용하였을 때, 모델의 R2 값이 유지되었으며, 이는 본 연구에서 도출한 MLR 및 SVM 기반 모델과 선행연구의 결과와 상반된 경향이었다(Kang et al., 2024; Dai et al., 2025; Mundada and Jain, 2025; Tikuye and Ray, 2025). 일반적으로, ML 모델은 테스트 데이터를 대입함에 따라 모델의 성능은 감소하는 것으로 보고되나, 본 연구에서 도출한 RF 기반 모델은 데이터 유형과 feature 축소에 상관없이 안정적인 성능을 나타내었다. 이러한 모델의 성능은 알고리즘별 데이터 관계 해석 능력이 기인하며, MLR 및 SVM 알고리즘은 주로 토양 색상과 OM 함량을 선형 관계를 가정하여 예측하는 반면, RF 알고리즘은 토양 색상과 OM 사이의 비선형 관계를 포함한 앙상블 트리를 구성하여 모델의 설명력을 향상시킨다(Schapire, 1990; Kang et al., 2024). 이러한 안정적인 모델 성능은 측정된 OM 함량과 예측된 OM 함량의 유의한 차이를 나타내는 3종의 오류지표에도 영향을 미치며, 많은 선행연구에서는 모델의 R2 값이 높아질수록 MSE, RMSE, 그리고 MAE값은 감소한다고 보고하여 본 연구와 유사한 경향을 나타내었다(Heil et al., 2022; Kang et al., 2022; Ho et al., 2025; Mundada and Jain, 2025). 또한, 본 연구에서 논 토양은 다른 토지이용 유형보다 높은 모델 성능을 나타내었다. 논 토양은 상대적으로 밭 혹은 과수원 토양에 비해 수분 관리가 일정하며 경작되는 작물 유형과 방식이 유사하여 토양 OM 함량의 변동성이 상대적으로 낮아 색상 기반의 예측 모델에서 높은 성능을 보인 것으로 판단된다(Kim et al., 2024). 하지만, 본 연구에서는 제어된 실내 형광등 조건에서 토양 색상을 얻었으며, 이는 실제 농업 현장에서의 광원 변동, 토양 함수 비, 거리 및 각도에 따라 모델의 성능은 달라질 수 있음을 시사한다. 실제로, Fu 등(2020)에서도 토양 수분 변동에 따라 모델의 R2 값은 0.2 - 0.6 사이의 범위에서 변동된다고 보고하였으며, 이는 추후 현장 모니터링 기술로 활용되기 위해서는 현장의 광원 및 토양 조건을 반영하는 지표를 필수적으로 포함해야 함을 나타낸다.
토양 OM 예측 모델 검증
모델의 일반화된 성능을 확인하기 위한 LOSO와 10-fold cross-validation 결과는 각각 Tables 3과 4에 나타내었다. 모델의 지리적 일반화 성능은 가장 시료 수가 많은 충청남도가 훈련 데이터로 포함된 모델에서 성능이 안정적으로 유지되었으며, 충청남도를 테스트 지역으로 설정한 MLR, SVM, 그리고 RF 모델의 R2 값은 각각 0.589, 0.623, 그리고 0.742로 가장 낮았다. 이러한 결과는 학습 데이터 내 포함된 타 지역의 토양 특성이 해당 지역을 대표하기에 충분하나, 모델 훈련을 위한 시료 수가 상대적으로 감소함에 따라 모델의 지리적 일반화 성능이 감소함을 시사한다. 모델의 성능을 무작위로 10회 반복하여 성능을 분석한 결과, RF 모델의 평균 R2 값은 0.769로 가장 우수한 성능을 나타내었으며, 학습 데이터의 구성 변화에도 불구하고 성능 편차가 매우 낮게 유지되어 모델의 높은 안정성을 입증하였다(Table 4). 상대적으로, MLR 및 SVM 모델의 R2 값은 각각 0.701과 0.699로, RF 모델 대비 상대적으로 데이터 분할에 민감한 경향을 나타내었다.
Table 3.
Predictive performance of three machine learning (ML) models for each regional fold.
Table 4.
Comparison of machine learning (ML) model performance using repeated 10-fold cross-validation.
| ML algorithms | R2 | RMSE (%) | MAE (%) |
| MLR | 0.701 ± 0.042 | 0.217 ± 0.085 | 0.129 ± 0.034 |
| SVM | 0.699 ± 0.078 | 0.225 ± 0.048 | 0.136 ± 0.029 |
| RF | 0.769 ± 0.033 | 0.187 ± 0.041 | 0.108 ± 0.045 |
모델의 성능을 객관적으로 평가하기 위해 수행한 LOSO 및 10-fold cross-validation은 공통적으로 RF 모델은 실내 규모에서 안정적인 성능을 나타냄을 시사하였으며, 이는 앙상블 모델의 높은 회귀 성능을 나타낸 많은 선행연구와 일치하는 경향이었다(Heil et al., 2022; Kang et al., 2024; Lee et al., 2024; Dai et al., 2025). 하지만, 본 연구에서는 모델 훈련에 사용된 시료 수가 줄어들면서 일부 ML 모델의 성능이 감소하는 경향을 나타내었으며, 이러한 결과는 ML 모델 개발 시 안정적인 성능을 위한 충분한 시료 수를 확보하는 것이 중요함을 시사한다.
Conclusion
본 연구에서는 스마트폰으로 추출한 토양 색상 정보와 3종의 머신러닝(ML) 알고리즘을 이용하여 토지이용 유형별 토양 유기물(OM) 함량 예측 모델을 개발하였다. 예측 모델 개발에 사용된 토양 색상 변수는 토양 OM 함량과 유의한 음의 상관관계를 보였으나, 색조와 관련된 h* 변수는 유일하게 양의 상관관계를 나타내었다. ML 알고리즘 별 OM 예측 성능 비교 결과, 랜덤 포레스트(RF) 기반 모델은 데이터 유형에 상관없이 안정적인 예측 성능을 보이는 반면, 다중선형분석(MLR)과 서포트 벡터 머신(SVM) 기반의 예측 모델은 테스트 데이터를 적용함에 따라 모델 성능이 감소하는 경향을 나타내었다. 또한, 이러한 모델 성능은 4종의 오류 지표와 유사한 경향을 나타내어 모델의 R2 값이 증가할수록 오류 수준은 감소하였다. 이러한 ML 기법을 활용한 접근은 Tyurin 및 Walkley-Black 법을 이용한 토양 OM 함량 분석 시간을 최대 66% 감소시킬 뿐만 아니라 비용적 부담을 완화시킬 수 있을 것으로 기대된다. 따라서, 스마트폰 기반의 토양 색상 정보와 ML 기법의 조합은 기존 OM 분석의 한계점을 효과적으로 보완할 수 있는 잠재적인 대안으로 활용될 수 있음을 시사한다. 하지만, 본 연구에서는 토양의 층위에 따른 색상 변화는 고려되지 않아 표토층에 대해 제한적으로 적용될 수 있으며, 추후 연구에서 철 혹은 망간 산화물의 환원반응과 같은 토양 색상 교란 요인을 고려한 모델 개발이 필요할 것으로 생각된다.
